CS-466/566: Math for AI
Module 01: MinMax Optimization
2026-03-23
Where Are We Now?
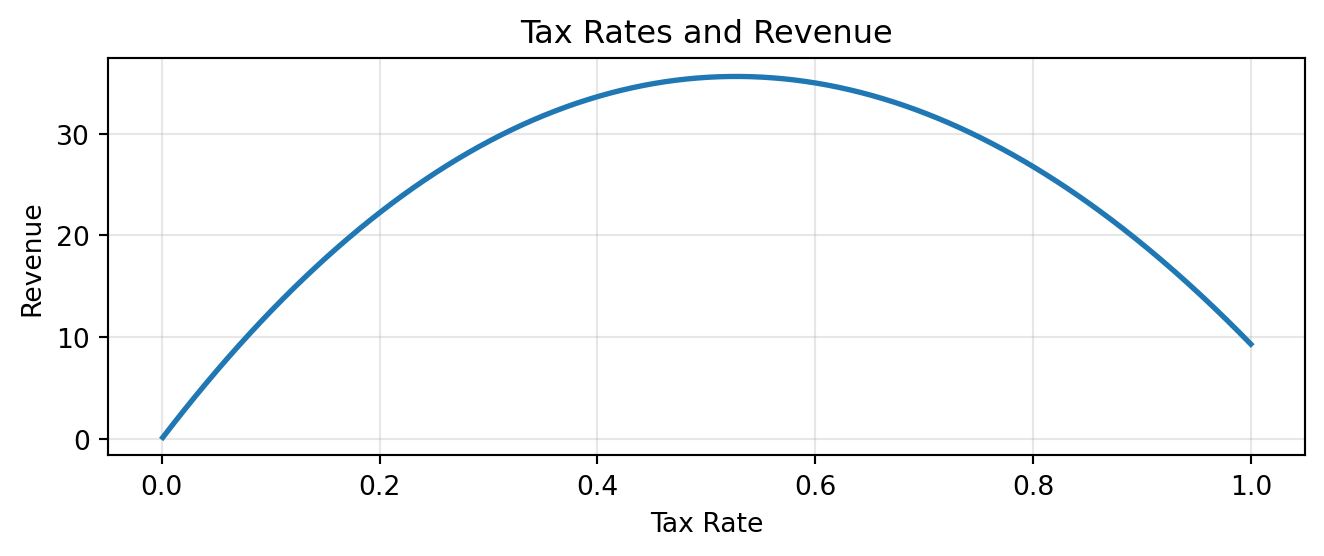
Your country currently has a 70% flat tax. Is this optimal?
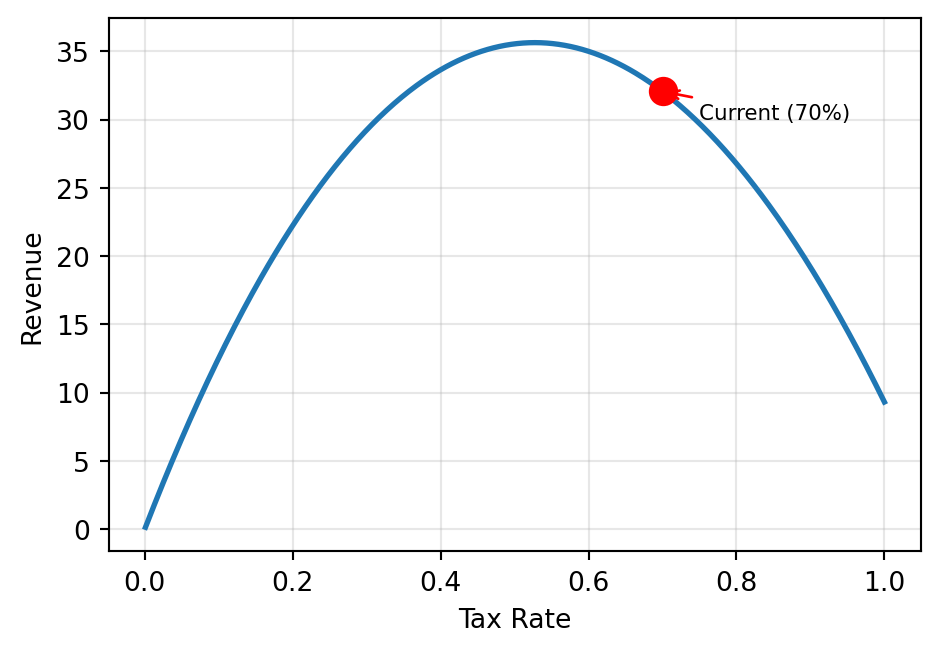
current_rate = 0.7
xs = np.linspace(0.001, 1, 500)
ys = [revenue(x) for x in xs]
fig, ax = plt.subplots(figsize=(5, 3.5))
ax.plot(xs, ys, linewidth=2)
ax.plot(current_rate,
revenue(current_rate),
'ro', markersize=10)
ax.annotate('Current (70%)',
xy=(current_rate,
revenue(current_rate)),
xytext=(0.75, 30), fontsize=8,
arrowprops=dict(arrowstyle='->',
color='red'))
ax.set_xlabel('Tax Rate')
ax.set_ylabel('Revenue')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()We need a precise answer — not just a guess from the plot!
What Does the Derivative Sign Tell Us?
Negative derivative at the red point:
→ Function is going downhill
→ To increase \(f\), move left (decrease \(x\))
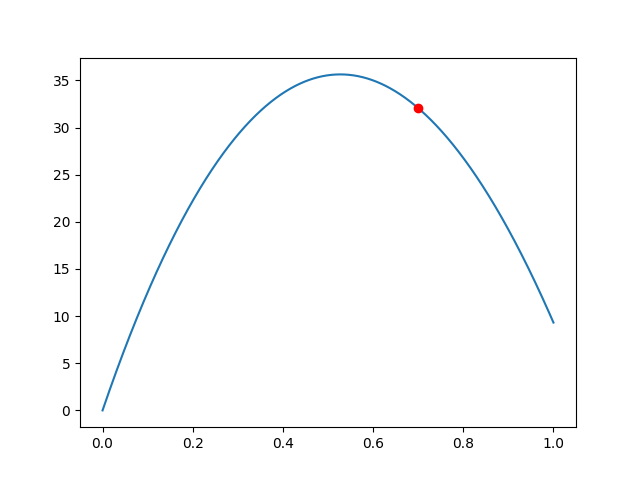
Positive derivative at the red point:
→ Function is going uphill
→ To increase \(f\), move right (increase \(x\))
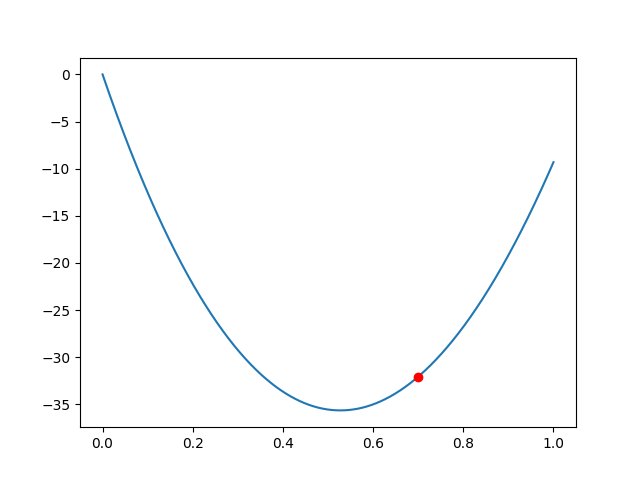
Visualizing Gradient Ascent
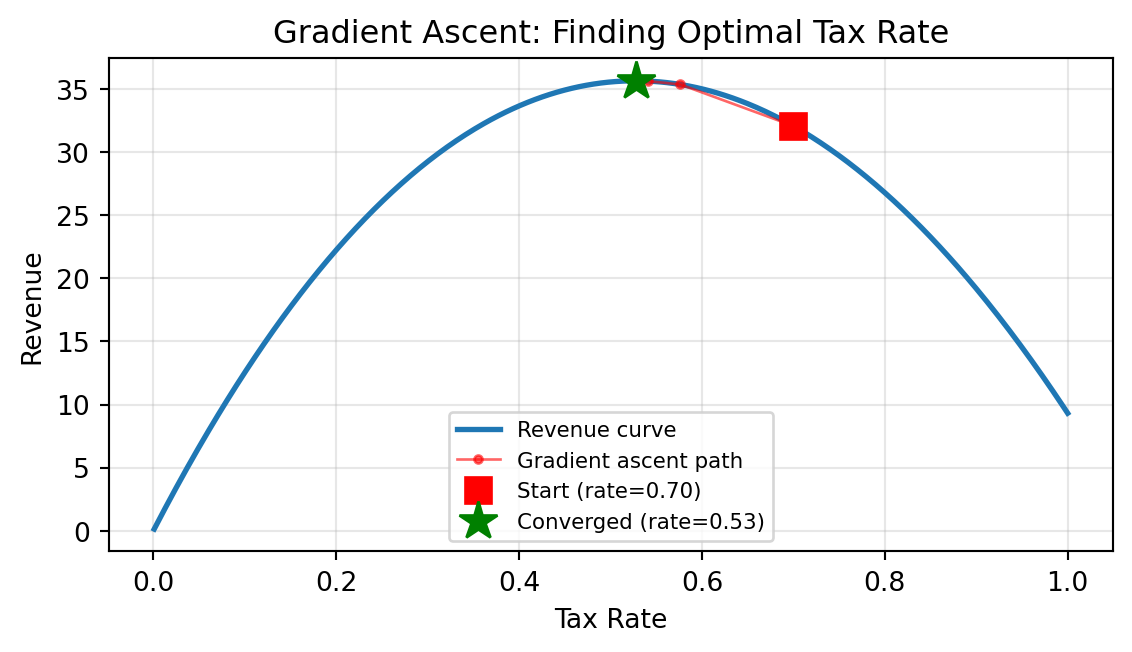
Starting from 70%, gradient ascent converges to the optimal tax rate in a few dozen steps.
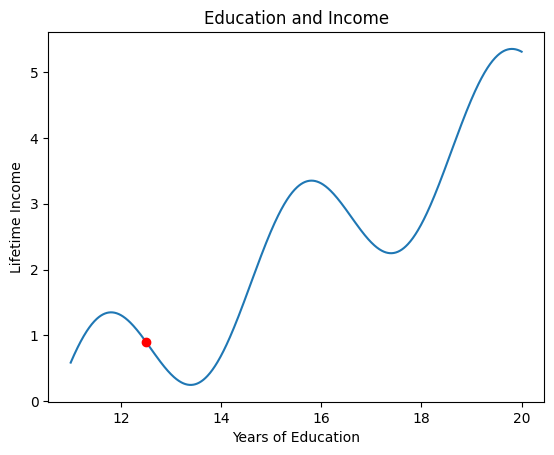
Education and Income: A Real-World Analogy
The Trap of Local Optima:
- Dropping out of school gives immediate income
- But staying in school → higher long-term earnings
- You must temporarily decrease income to reach the global maximum
Gradient ascent is greedy — it can’t see the bigger picture.
Thank You!


